

JMDC データウェアハウス開発本部の髙野です。
医療ビッグデータ事業を展開するJMDCでは、様々な医療データを取り扱い、価値創出へとつなげています。医療データと言っても、その種類や役割は実に幅広く、多岐にわたっています。
以前掲載した【エンジニア向け】医療データの種別を超解説 Vol.1〜保険者データ編〜という記事では、主に保険者データについて解説しました。今回は、第2弾として「医療機関データ」についてお伝えしていきます。
<プロフィール>
株式会社JMDC データウェアハウス開発本部 医療機関基盤グループ
医療機関向けのシステム開発、導入、保守を経験後、2019年11月、JMDCに入社。医療機関データベースの運用改善を担当後、オンプレからクラウド(AWS)への刷新に従事。現在は、刷新後の医療機関データベースの運用や新規開発案件に取り組む。
医療機関から預かったデータをもとに解析サービスを提供
JMDCでは、健康保険組合や医療機関から提供されるデータから、それぞれ「保険者データベース」と「医療機関データベース」を構築しています。
医療機関データベースは、下図にあるように、医療機関や製薬・生命保険会社、官公庁、研究機関向けの解析サービスに使われています。

医療機関データは、総合病院やクリニックから受領する複数のデータです。JMDCでは医療機関支援事業の契約先である医療機関から集めたデータを活用しています。
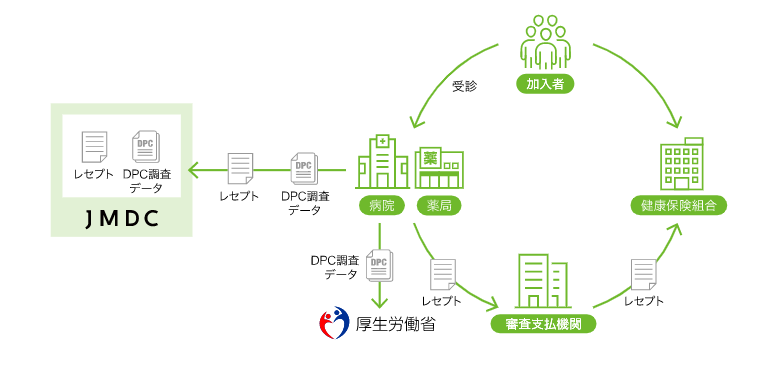
医療機関支援事業では、JMDCが蓄積する膨大なリアルワールドデータと、様々な医療機関データを分析・解析・モデリングすることで、医療機関の診療の質指標(Quality Indicator=QI:医療の質指標、臨床指標)の作成サポートや、経営改善コンサルティングなどを実施しています。

では、医療機関データの中身について見ていきましょう。
私たちが扱うデータには、以下の3種類があります。
【1】レセプトデータ
医療機関が保険者に医療費を請求する際に必要となる診療報酬明細のデータです。医療機関データベースでは、審査支払機関に提出する前のレセプトを利用しています。
レセプトは診療報酬制度に基づいた記載の仕方があり、元々が紙だったものを再現が目的のため、独特な記録方法となっています。例えば、診療明細情報だけを見てみても、医療行為は主な行為(手技など)と使用した薬剤、材料をまとめて記録します。下図は、注射とその注射で使った薬剤の例であり、「診療識別」が記録されたところがグループの始まりとなります。
そして、グループ内で診療行為、薬剤、材料別に点数計算されて、最後の行に点数が記録されます。同じ内容を月に複数回行った場合は、1日~31日の情報カラムの実施日のカラムに回数が記録される仕様となっています。

【2】DPC調査データ
DPCとは、診断群分類別包括評価と呼ばれるもので、分類ごとに1日当たりの入院費用を定めた医療費の計算方式です。従来の計算方式(出来高払い方式)では、診療で行った検査、注射、投薬などの量に応じて医療費が計算されていましたが、DPCでは病名、手術、処置などの内容に応じた1日当たりの定額の医療費を基本として計算を行っています。
この制度の目的は、医療の質の向上と入院期間の短縮にあるとされています。
DPC調査データは、国がDPCの導入の影響評価及び今後のDPC制度の見直しを目的に医療機関から集めているデータです。レセプトの診療明細や退院患者のカルテ情報などが含まれています。もともと分析目的のデータのため、比較的テーブル化しやすいデータです。
代表的なファイルの1つとして「様式1」と呼ばれる患者の1入院ごとの情報を記録したファイルがあります。基本、1入院で1つ作りますが、入院期間中に病棟の種類が、一般病棟から療養病棟に移った場合などは全入院期間分と、一般病棟期間分、療養病棟期間分を作成するといったルールがあります。こういったデータ構造を把握できていないと、作成するテーブル上、レコードが余計にできてしまったり、必要な情報が全てとれなかったりします。例えば、下図のとおり、
・性別はどれか1つから取得すれば良い。
・傷病名は、全てからとらないと網羅できないが、全てからとると、重複するデータもある可能性がある。
といったものです。

【3】検査値データ
医療機関内で検査した際のデータで、血液検査、尿検査などの検体検査の結果値が含まれますので、投薬の結果、症状の改善の経過を分析等に重要なデータとなります。検査値データは、医療機関のシステムから直接抽出しています。医療機関ごとにシステムが異なり、定型のデータとして抽出するのが難しいため、抽出したデータを別のシステムで標準化した後に医療機関データベースに取り込んでいます。
これらのデータを蓄積し、医療機関データベースを作っています。データベースには、541の医療機関(2014年4月~2022年1月までの累積数)からのデータが含まれており、病院の契約数は年々増加しています。
レコード数で最も多いものがDPC調査データにある入院費の明細で約45億レコードと、膨大な量を扱っています。
医療機関データベースは、レセプト、DPC調査データ、検査値データの3種を個別の患者IDで紐づけているのが特徴です。患者IDを表すデータがそれぞれ異なる形で記録されているため、そのままでは同一患者と見なすことができません。3種類のデータをつながるように名寄せすることで、同一患者データとして捉えることができるようになります。
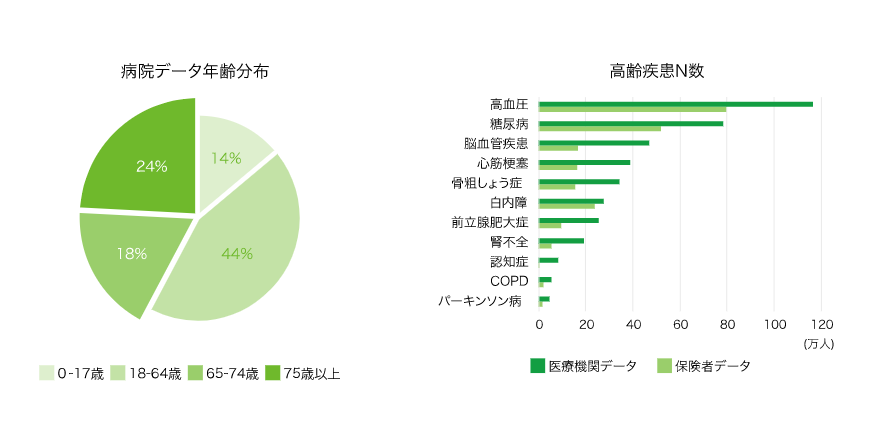
また、患者の年齢層にも特徴があります。どの保険に加入しているかに関わらず、医療機関を受診した患者が対象になるため、65歳以上の高齢者を豊富にカバーしています。
AWS Athenaでスピード処理
ここでは、データを収集してから、データベースを作るまでの流れについてお伝えしていきます。
(1)データを収集:JMDCの医療機関支援の部門が契約先の医療機関からデータを収集する。その際に匿名加工処理を施す。
(2)データのテーブル化:ここから私が所属する医療機関基盤グループが担当。レセプトは複数レコードで1つのレセプトを表現しているが、先頭カラムのレコード識別によってカラム数が決まるため、それらを分解してテーブル化。DPC調査データはほぼそのままテーブル化。
(3)クレンジング:600項目ほどのクレンジング項目を基準にイレギュラーなデータをクレンジングする。日付の妥当性、数字が入る箇所に文字が入っている、入力可能な選択肢以外の値等をデータの精度を上げるためNULL値等に更新する処理。
(4)標準化:マスタや辞書と照らし合わせて、コード化されていない情報をコード化する。
(5)マージデータ作成:レセプトとDPC調査データを合わせたテーブルを作る。
(6)最後に出来上がったデータのチェック、必要に応じて再処理を行い、各種集計資料作成後、後続のサービスへ提供する。
医療機関データベースでは、AWS S3にデータレイクを構築しています。上記の(2)~(5)の工程は、AWSのAthenaを使って約30時間で処理しているのが特徴です。以前はオンプレのシステムを使っており、月次処理に3週間近くかかっていたのですが、AWSに刷新したことで大幅に短縮することができました。このあたりのシステム刷新については、こちらの記事(医療機関データのオンプレ → クラウド移行にかけた1年と、6倍の効率化について)に詳しく載っていますのでぜひ読んでみてください。
サービス提供部門からの要望や診療報酬改定などで、今後もデータベースを改善していく必要があるので、やはり前項のような医療機関データならではの特徴をキャッチアップすることは業務上大事なことの1つになってきますね。
大規模データやクラウド導入で、新たなスキルを習得
私はJMDCに入社前は病院向けのシステムの導入・保守をやってきた期間が長く、病院は通常の診療終了後も夜間診療や救急外来などを行っており、システムを止めることの影響が大きい中でのシステム移行やリリース作業などを経験してきました。現在の医療機関データベースの運用でも、手順を整備して、それを確実に実行していかなくてはならない部分に過去の経験を活かせていると感じています。
一方で、これまで経験のないことにも数多くチャレンジできています。先ほどお話したシステムのリプレイスを通して、クラウドのインフラを初めて使うようになり、知見やスキルの幅が一気に広がりました。ECSタスクを使った並列処理を行うシステム構成や、他アカウントとのデータ連携などAWSの知見を深めることが出来ました。データの規模も一般的なシステムで扱うデータの量とは比にならないくらい大規模ですから、並列でいかに速く処理するか考えるなど、パフォーマンスチューニングの技量を伸ばせていると実感しますね。
中には地道な確認作業も多く、根気強さがモノを言うこともありますが、最善のデータベースを作ってサービス提供に貢献できる、やりがいのある仕事なのではないかと思います。
今後の取り組みとしては、医療機関向けサービスの拡充にともない、データをお預かりしてからより速くサービスを提供することが求められています。従来とはデータベースを作成するタイミングや頻度なども変わってくるのではと考えており、今後処理基盤の分離なども検討予定です。
最後までご覧いただきありがとうございました。
もし少しでも弊社にご興味をお持ちいただけましたら、こちらの採用ピッチ資料に詳しいことが記載してありますので、ぜひ一度ご覧ください。